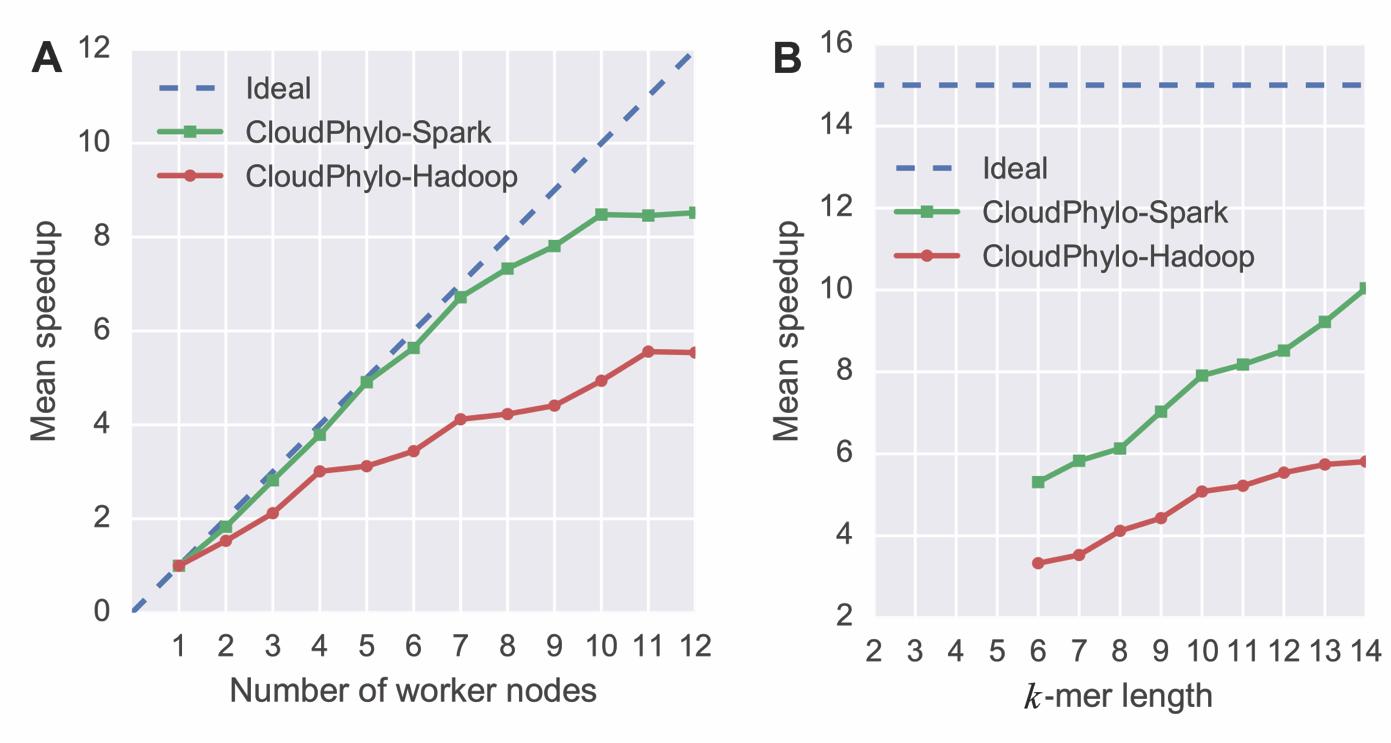
Phylogeny reconstruction is a routine analysis for most evolutionary related studies, determining and picturing evolutionary relationships among many genes or species. However, most existing tools for phylogeny reconstruction are simply based on single process model or traditional parallel paradigms, such as PThread, OpenMP etc., and therefore, cannot scale well with the dramatically increasing size of input dataset. To tackle this challenge, BIGD (Big Data Center; http://bigd.big.ac.cn) presents a Spark-based tool, CloudPhylo, to handle large dataset for fast and scalable phylogeny reconstruction Spark is a newly proposed cloud computing framework, which incorporates MapReduce paradigm and efficiently caches internal calculation results, significantly boosting the performance of CloudPhylo and enabling CloudPhylo to be used for largescale phylogenetic tree inference. CloudPhylo is not only the world’s first phylogeny reconstruction tool available for large-scale dataset, but also the first Spark-based bioinformatics software in China. According to the comparison results, CloudPhylo achieves high efficiency and good scalability, and is well suited for largescale phylogenetic tree inference (Figure 1).
In order to make CloudPhylo more accessible and usable for researchers, we deployed CloudPhylo in Qomo Cloud Platform (https://cloud.big.ac.cn/users/bigd/tools/clouldphylo) of BIGD. This work has been published in the journal of Bioinformatics (http://bioinformatics.oxfordjournals.org/content/early/2016/10/14/bioinformatics.btw645). This work is supported by National Programs for High Technology Research and Development [2014AA021503 and 2015AA020108], and International Partnership Program of Chinese Academy of Sciences [153F11KYSB2016008]. Paper link:http://bioinformatics.oxfordjournals.org/content/early/2016/10/14/bioinformatics.btw645 Figure 1. Speedup of CloudPhylo under various workload