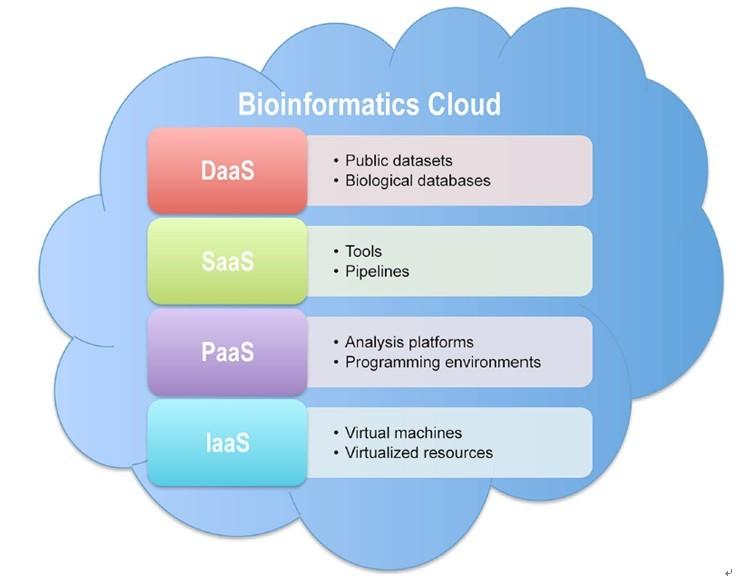
With the fast growing of high-throughput sequencing technologies, biological data is expending dramatically. Bioinformaticians are facing difficulties in storage and analysis of such vast amounts of data. As establishing and maintaining computational infrastructures for data processing are real headache for many laboratories and institutions, cloud computing has become a promising solution. A review recently published in Biology Direct has focused on the bioinformatics clouds for big data manipulation by Professor ZHANG Zhang and his team at Beijing Institute of Genomics (BIG), Chinese Academy of Sciences (CAS). Cloud computing makes the best use of multiple computers to provide convenient and on-demand access to hosted resource via Web Application Programming Interfaces (API). In the review, authors classified the existing cloud-based resources in bioinformatics into these four categories: Data as a Service (DaaS), Software as a Service (SaaS), Platform as a Service (PaaS), and Infrastructure as a Service (IaaS). The authors also present their perspectives on the adoption of cloud computing in bioinformatics research, such as placing data and software into the cloud; big data transfer; a cloud-based lightweight programming environment; open bioinformatics clouds. (Refer the article for details: http://www.biology-direct.com/content/7/1/43) It is summarized that, in the era of big data, bioinformatics clouds should integrate both data and software tools, equip with high-speed transfer technologies and other related technologies in aid of big data transfer, provide a lightweight programming environment to help people develop customized pipelines for data analysis, and most important, be open and publicly accessible to the whole scientific community. Illustration of bioinformatics cloud. (Imaged by Prof. ZHANG Zhang) Contact: Prof. ZHANG Zhang Email: zhangzhang@big.ac.cn