Researchers Develope Deeply Integrated Multi-omics Database for Soybean: SoyOmics
Soybean (Glycine max (L.) Merr.) is a worldwide crop providing large amount of plant oil and protein for people. Improvement of soybean production and quality is the key task for geneticists and breeders. Boom of genomics convenience the study and breeding of crops, as well as soybean. Nowadays, data expands sharply at both dimension and size level, which brings challenges for researchers to deal with these big omics data.
In a study published in Molecular Plant, researchers led by TIAN Zhixi from the Institute of Genetics and Developmental Biology (IGDB) of the Chinese Academy of Sciences (CAS), ZHANG Zhang and SONG Shuhui from Beijing Institute of genomics/China National Center for Bioinformation, CAS, have made contribution to draw an innovative framework of soybean multi-omics data and built the database: SoyOmics.
The researchers collected 29 de novo assembled genomes of different soybean accessions, ~550 thousand large scale structural variations (SVs), graph pan-genome, six genomes of species of subgenus Glycine, ~3,000 soybean germplasms and ~38 million SNPs and INDELs from them, 28 or 9 tissue-stages gene expression data of ZH13/WM82 or pan-genome accessions, and ~27 thousand records of 115 soybean phenotypes from different years and areas of planting. Knowledge of quantitative trait locus (QTL), genome-wide association study (GWAS), and functional genes were also embodied. These multi-omics data can be classed into six basic modules: Genome, Variome, Transcriptome, Phenome, Homology and Synteny.
Based on those, researchers designed analysis modules for BLAST search (BLAST), GWAS (easyGWAS), gene expression pattern (ExpPattern), haplotype (HapSnap), genome position transform (VersionMap) and Soybean array (SoyArray).
SoyOmics can meet the searching demands for genomic regions, genes, variations, germplasms, phenotypes and/or any available biological knowledge related to soybean. Each searching result has effective crossover with other related entities in the database. The application toolkits afford several one-stop resolution for genetics, genomics and/or bioinformatics analysis. In addition, SoyOmics will be continuously updated to make it as a vigorous and up-to-date database. It appreciates global collaborations to build it as a valuable platform for the whole research community around the world.
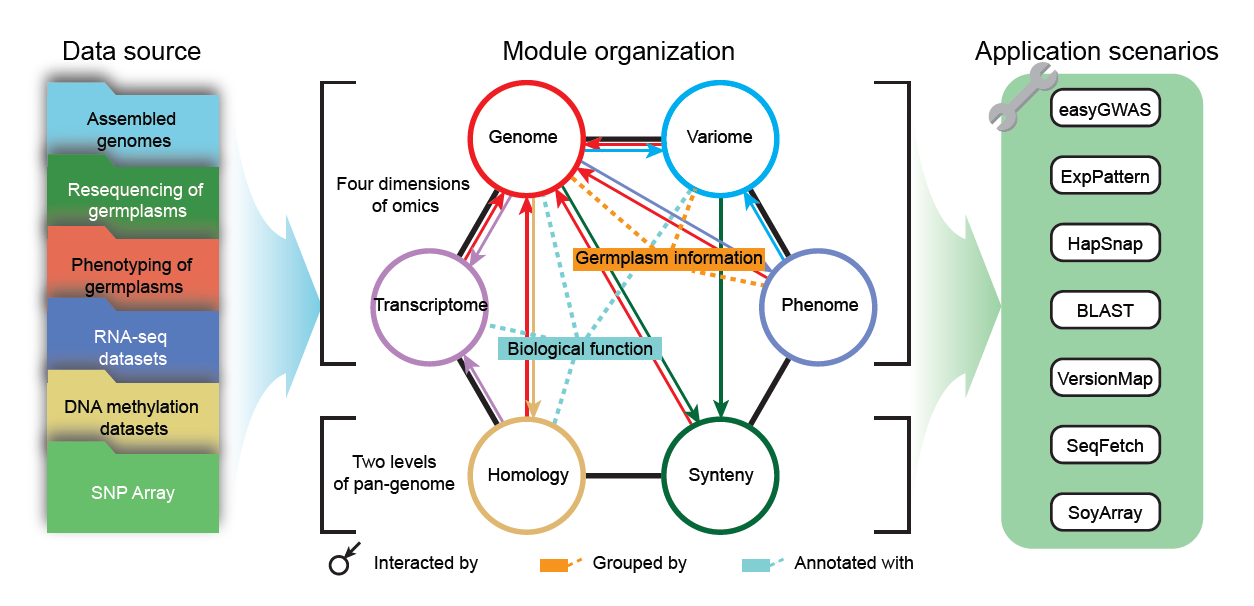
Framework of SoyOmics, including data source, module organization and application scenarios.
Database link of SoyOmics: https://ngdc.cncb.ac.cn/soyomics/
Demonstration video link of SoyOmics: https://ngdc.cncb.ac.cn/soyomics/documentation